The Album Discoverer
Who Still Listens to Albums?
Before the days of streaming music and listening to MP3s, I spent a decent chunk of money on buying CDs. The act of popping a newly acquired CD into a player and listening to an album in its entirety is a lot less familiar now, partly because no one buys CDs anymore, but also because listening to music has changed. With the advent of streaming music, it’s become much easier to make and listen to playlists. Thanks to Spotify, the playlist is easier to create and distribute than its predecessor, the mixtape/burned CD, and now playlists are everywhere.

With this change comes the reduced significance of the album, which is unfortunate. Musicians often conceptualize their work as an album, with an intended track order and overarching themes. Choosing which tracks to include on an album and in what order, is an artistic choice, and the track progression on an album and its overarching themes get lost when songs are taken out of context and put into a playlist. I can’t count the number of times I’ve rocked out to a Janelle Monáe song in a playlist, only to be disappointed that the next track in the playlist isn’t what comes next on the album.

Given this, I wanted to create a music recommender that focused on recommending albums, rather than individual songs to be put into a playlist. This led to building the Album Discoverer for my final project at Metis.
This post is a high-level look at how I built the Album Discoverer. If you want to see the code and documentation, please see my github repo. To try it out for yourself, navigate to the end of this post for the link to the Flask app.
Getting the Data
I started by scraping data from Metacritic to get their list of the 1000 top rated albums of all time, to use as the set of albums to recommend. I’m using Metacritic ratings as a proxy for album quality - I wanted to make sure any album I was recommending was “worth listening to”, at least according to critic reviews.
I fed each of these albums into the Spotify API to retrieve track data for each song on the album, getting back thirteen features for each track. These definitions come from the Spotify documentation.
| Feature Name | Description |
|---|---|
| Danceability | the suitability of a track for dancing, on a scale from 0-1 |
| Energy | the perceptual measure of intensity and activity, on a scale from 0-1 |
| Key | the estimated overall key of the track, as integers that map to pitches |
| Loudness | the loudness of a track in decibels, ranging from -60 to 0 |
| Mode | whether the song is in major scale (1) or minor scale (0) |
| Speechiness | the presence of spoken words, on a scale from 0-1 |
| Acousticness | a confidence measure of the acousticness of a track, on a scale from 0-1 |
| Instrumentalness | an estimation of whether a track has no vocals, on a scale from 0-1 |
| Liveness | the presence of audience in the recording, on a scale from 0-1 |
| Valence | the musical positiveness, on a scale from 0-1 |
| Tempo | the estimated tempo of a track in beats per minute |
| Duration | the duration of the track in milliseconds |
| Time Signature | the estimated overall time signature, the number of beats per measure |
Principal Components Analysis
Given the 13 track level features, I wanted to reduce the feature space into something more manageable. I scaled my features and performed a Principal Components Analysis to do some dimensionality reduction. I looked at both a scree plot and a plot of cumulative explained variance to determine how many components to use.
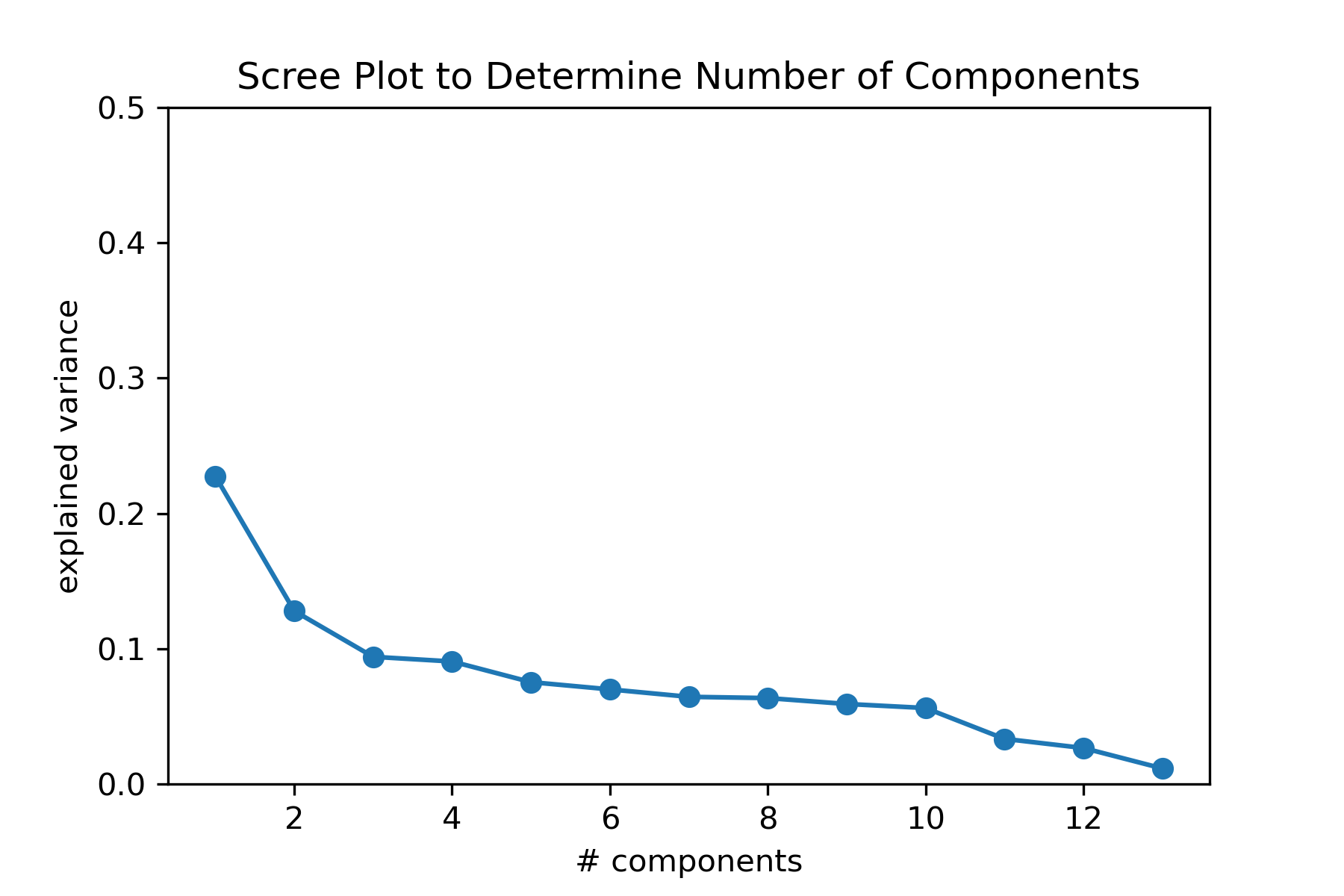
When interpreting this scree plot, I looked for an elbow, or a dramatic reduction in explained variance for an increase in number of components. There isn’t a clear elbow here.
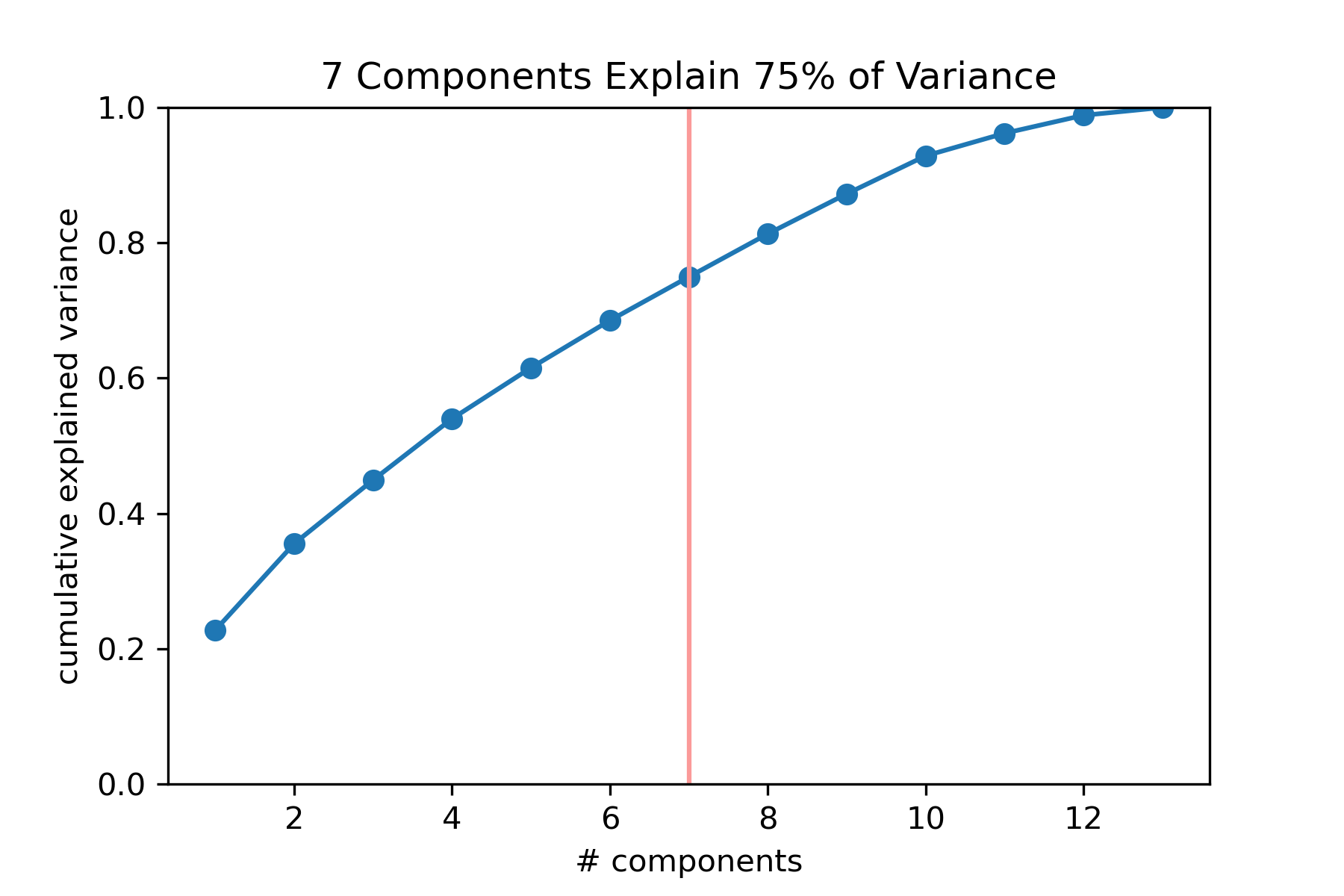
In the absence of a clear elbow, I opted to choose the number of components that would explain 75% of the total variance. So in the end, I chose 7 principal components, a little over half of the original number of features.
Once I had the principal components sorted, I aggregated them up on the album level, taking the mean of each principal component.
Artist and Genre - It’s Messy
Now I have a way to describe each each album, using the combination of the seven principal components as a vector for each album. I want to know that the vector actually describes each album in a way that makes sense to me as a listener, and isn’t clustering together albums that are very different from each other. I decided to plot each album in a 2-dimensional space, colored by artist genre, to visualize how well this works. I was hoping for some nice, clean clusters.

Before I could get there though, I needed to make sure using artist genre made sense. This is an artist-level feature on Spotify, which means that all albums by the same artist will have the same genres associated with it. This is a bit of an oversimplification, especially considering artists evolve, and their sounds change over time. For my purposes though, this is probably okay. My more pressing issue was how messy artist genre is. Depending on the artist, Spotify offers an extensive list.
Fiona Apple: ‘art pop’, ‘chamber pop’, ‘indie pop’, ‘lilith’, ‘permanent wave’, ‘piano rock’, ‘pop rock’, ‘singer-songwriter’
Janelle Monáe: ‘afrofuturism’, ‘alternative r&b’, ‘art pop’, ‘atl hip hop’, ‘dance pop’, ‘electropop’, ‘escape room’, ‘neo soul’, ‘pop’, ‘r&b’
If I wanted to plot albums by genre, I needed to pick the most salient genre for each artist. I decided to use CorEx for dimensionality reduction, to identify how many genres I needed, to best describe the different artist genres in the data.
Using CorEx for this is similar to using it for topic modeling. I’m trying to reduce the total number of genres for all albums in my dataset into a few that best describe most of the albums in the data. I did a few interations and ended up with 10 genres, plus a catch-all:
| Genre Name |
|---|
| Folk/Singer-Songwriter |
| Hip-Hop/Rap |
| Dance/Electronica |
| Metal/Classic Rock |
| Indie |
| Experimental |
| Alternative R&B/Indie Soul |
| Rock/New Wave |
| Electropop/Pop |
| Art Rock/Slow Core |
| Other |
Under these new genre categories, Janelle Monáe would be classified as Hip-Hop/Rap, and Fiona Apple would be classified as Folk/Singer-Songwriter. These seem like reasonable genres.
Validating My PCA
Now that I’ve got my genres sorted, I can plot the resulting components of my PCA with a t-SNE plot, and color it by genre.
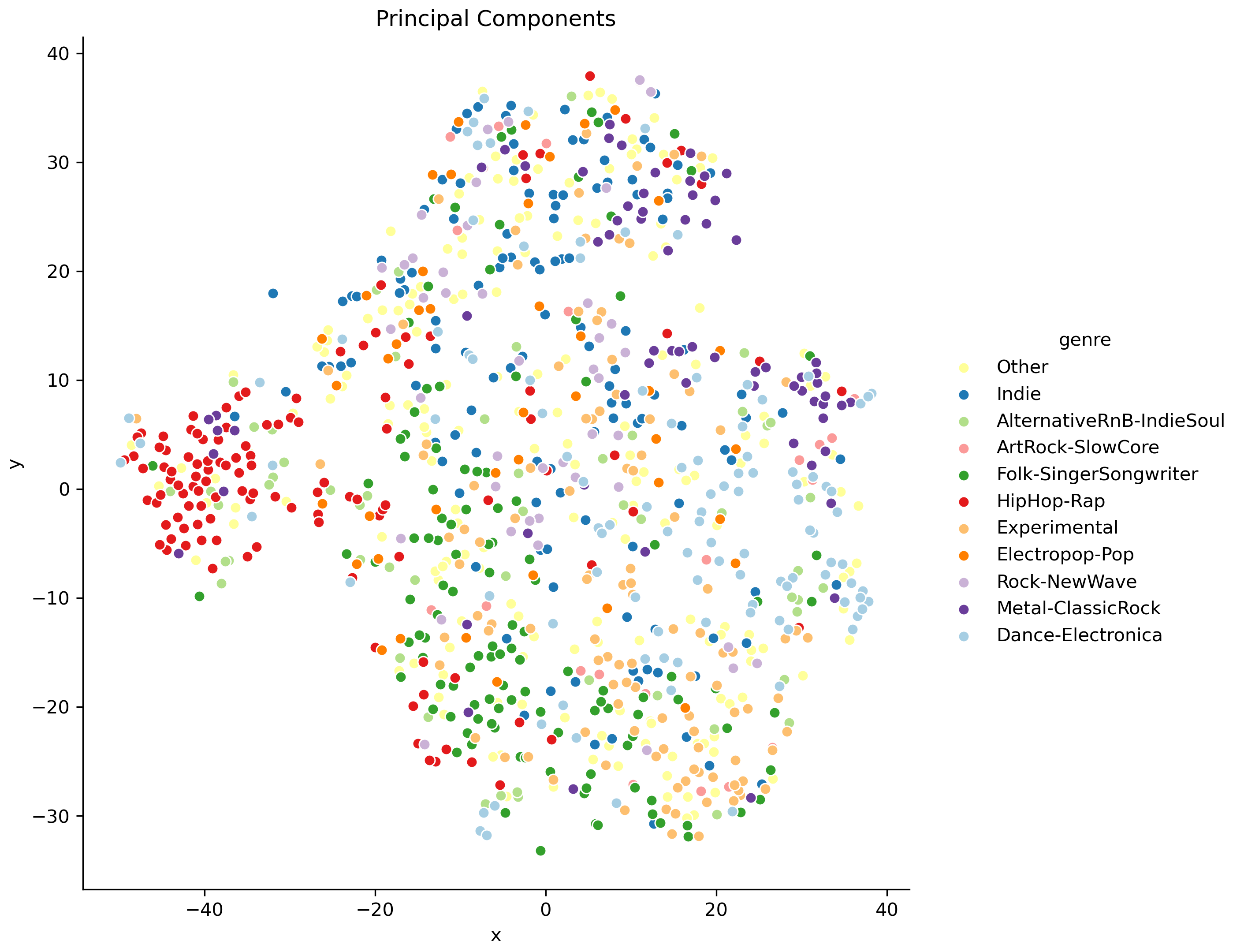
This plot suggests that the albums are clustering according to genre. It looks like the PCA did a reasonable job of extracting the important features of each album. Let’s take a closer look at a few of the genres.
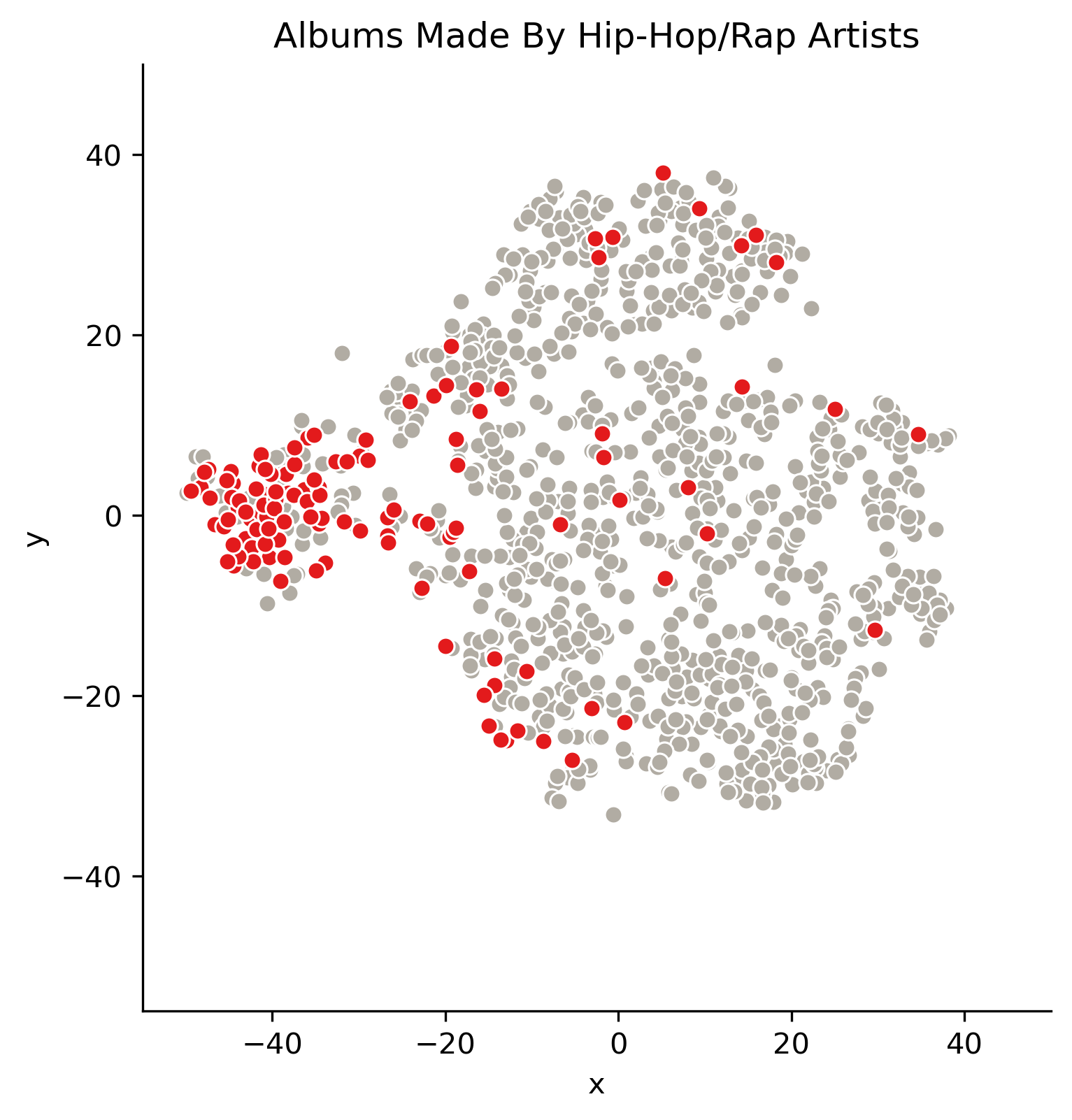
This is the most well defined cluster. Albums made by hip/hop rap artists seem to be localized to the far left.
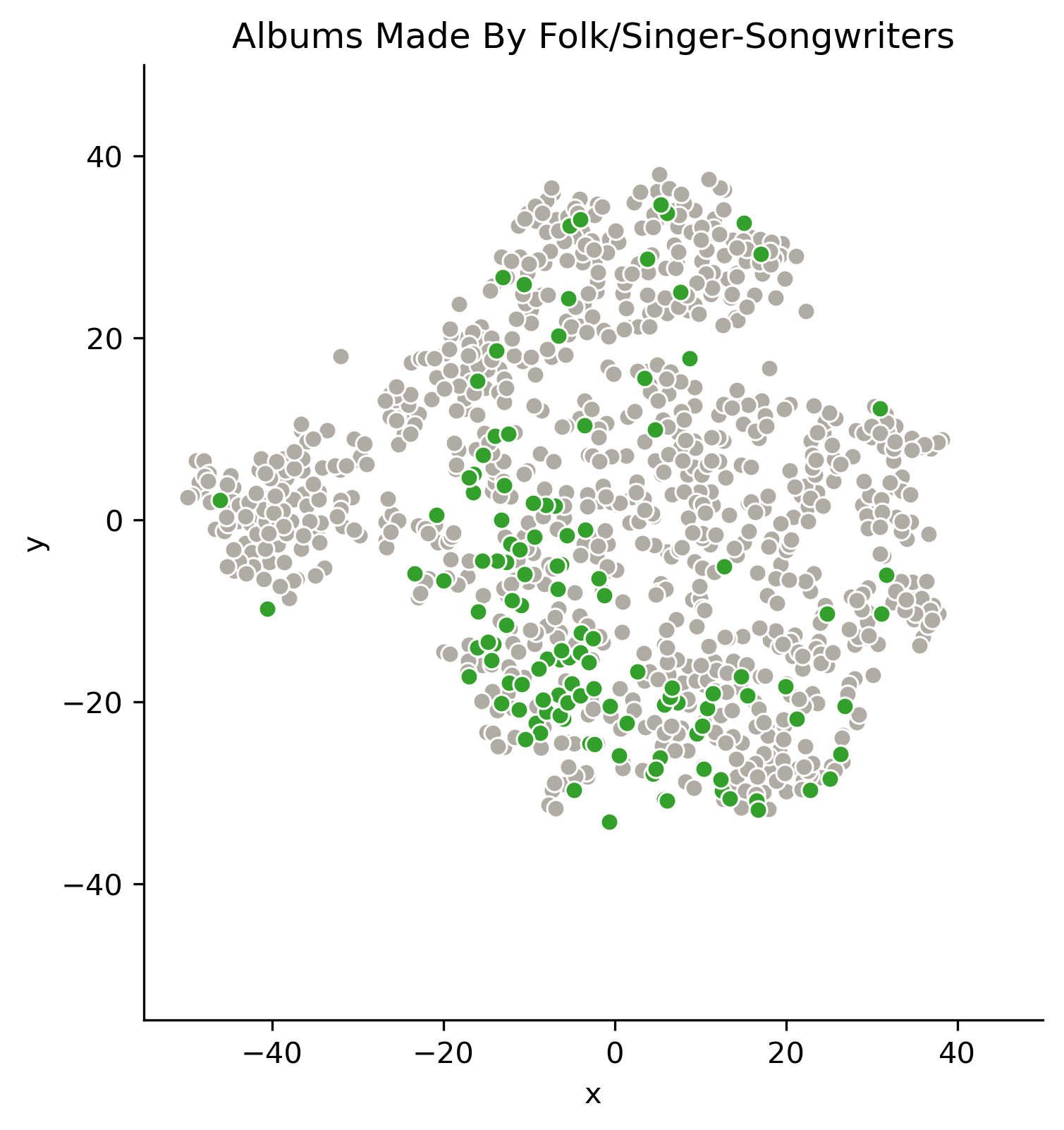
Albums made by folk/singer-songwriter artists are less clearly defined, but they are still generally in the lower left part of the plot.
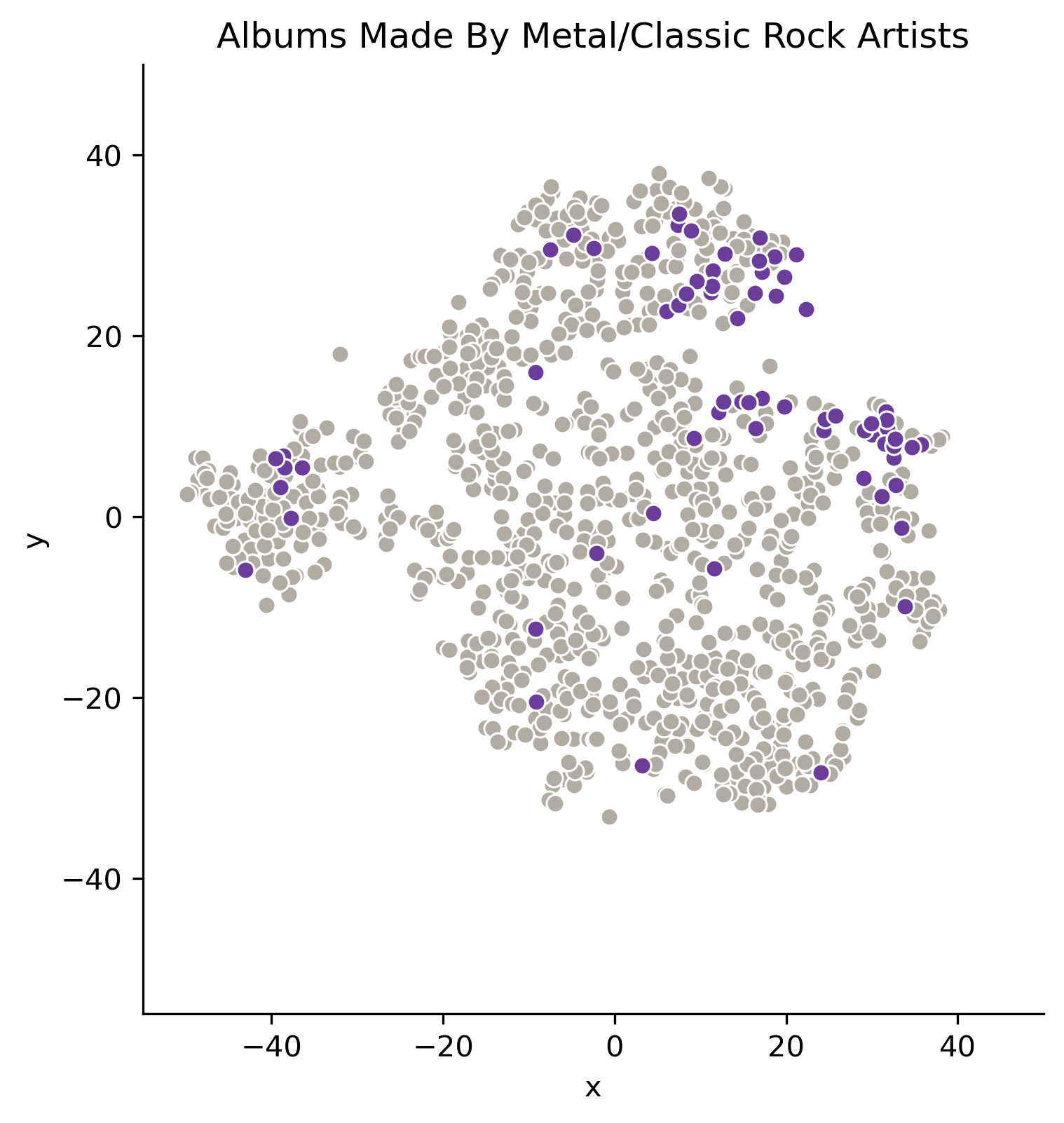
There are fewer albums by Metal/Classic-Rock artists, and they are mostly in the upper right part of the plot.
Based on these plots, I’m satisfied that I’m able to group albums together in a way that matches their genre.
Artist and Album Examples
Now I want to understand whether this method can differentiate between albums by the same artist, so I plotted a few artists with multiple albums in the data.
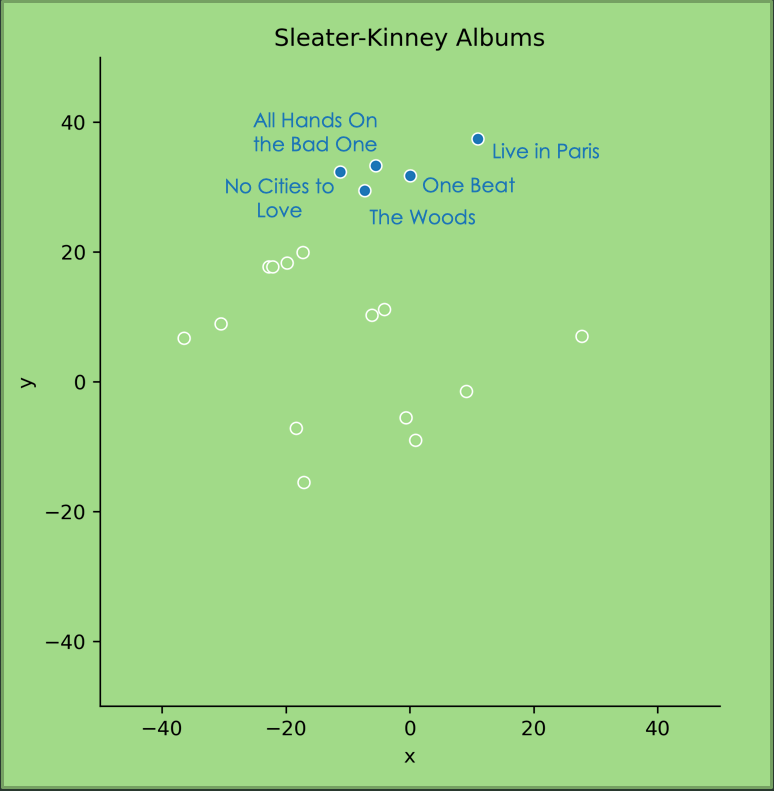
This plot is of five of Sleater-Kinney’s albums. They are pretty similar to each other, except for the “Live in Paris” album on the far right. This is the only live album of the five, and it makes sense that this would be considered different, especially knowing that Spotify has a feature that measures ‘liveness’.
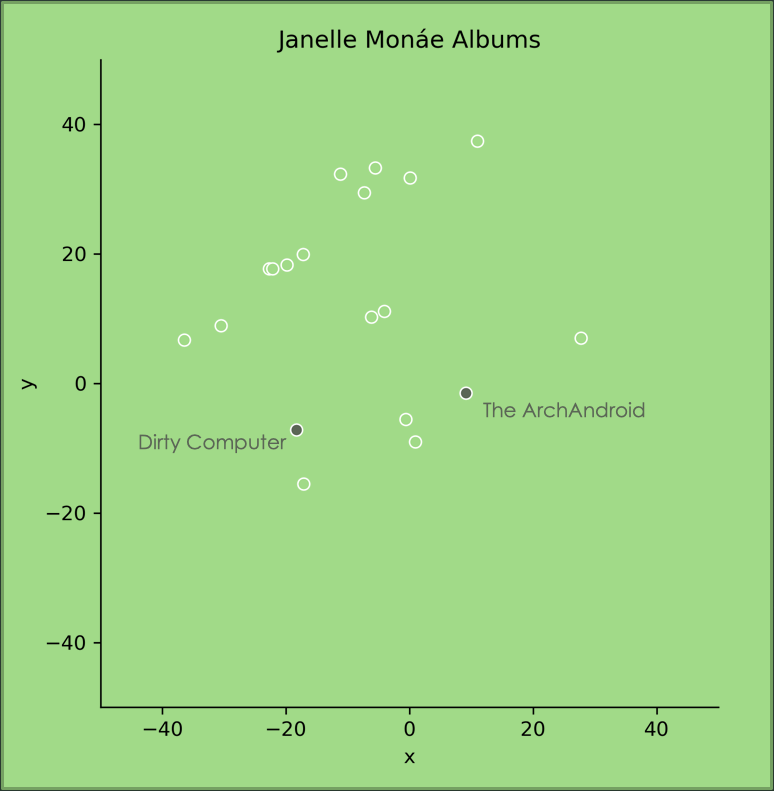
This plot shows two of Janelle Monáe’s albums (The Electric Lady didn’t make the cut, unfortunately). The two albums shown here are separated, which makes sense. The Archandroid was her first album, and it’s a lot more alternative and psychedelic. I would consider Dirty Computer to be more R&B and soul.
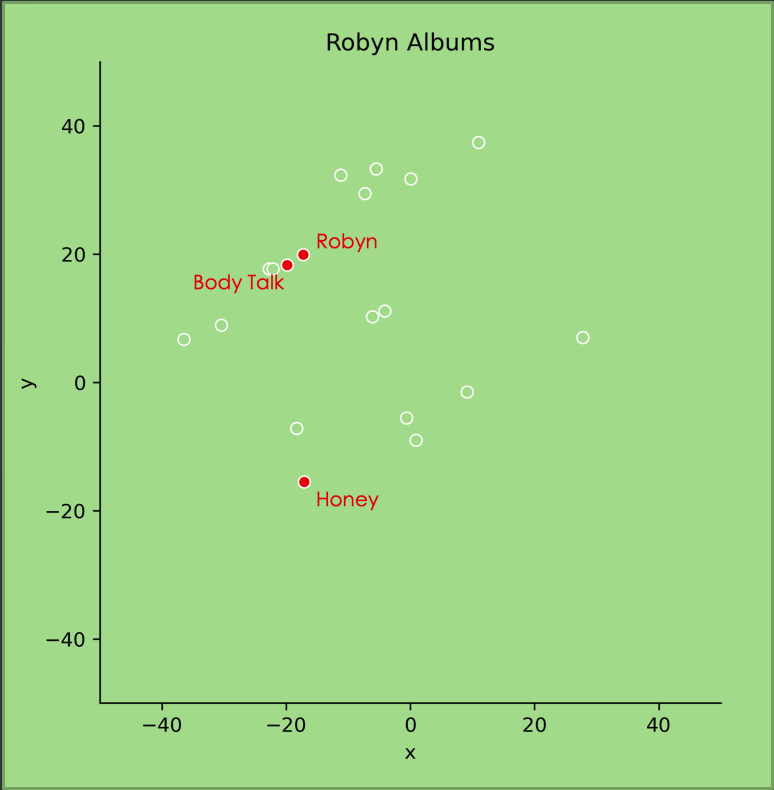
This plot shows Robyn’s albums, with two of her earlier albums clustered near each other, and her latest album, Honey, further away. I remember being surprised by Honey when I first heard it, because it’s much moodier than her previous work. This also makes sense to me.
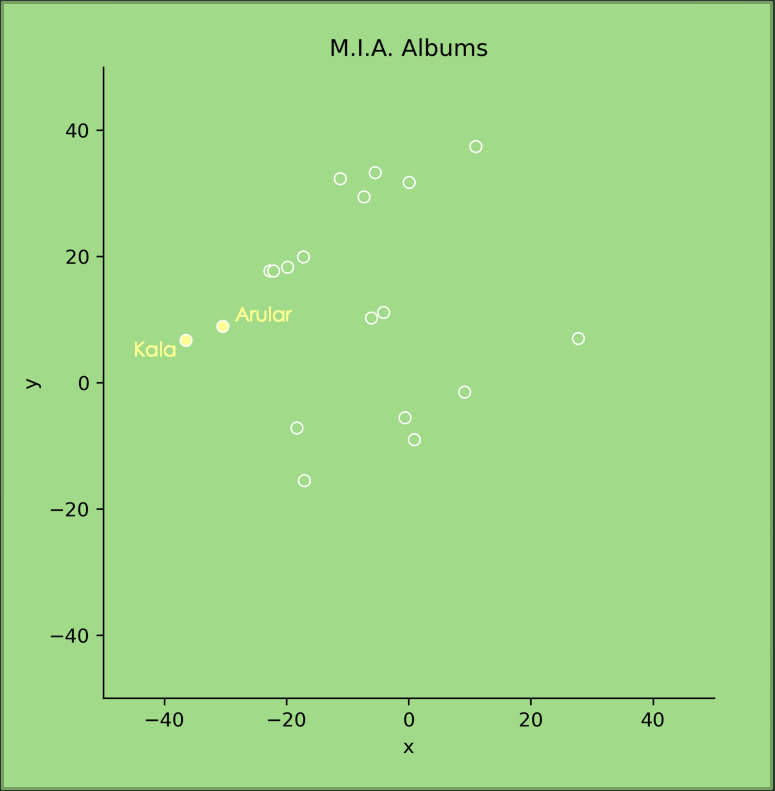
The last one I’ll show is a plot for MIA’s two earliest albums. I’m showing this plot to demonstrate that they’re similar, and they are clustering to the very far left, which is where we saw Hip-Hop/Rap clustering earlier. The genre assigned to MIA in the Spotify data is ‘art pop’, though I’d consider her more of a rapper, personally. This plot supports my opinion, demonstrating that the components can capture information that is different, and can be more accurate than the ‘genre’ designation.
Recommending Albums
Based on the plots and all of the exploration done thus far, I am fairly confident that this method can group similar albums next to each other, and separate dissimilar albums. Now I’m ready for the recommender.

To get recommendations, I started with the albums in the dataset, and calculated cosine distance between the components for each album, returning the the five albums with the largest cosine similarity. Given Janelle Monáe’s Dirty Computer, for instance, these are the five albums in the data that are the most similar:
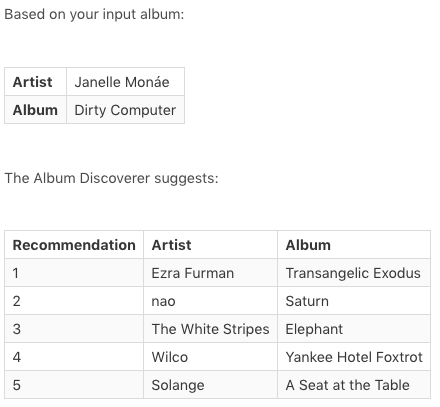
A Seat at the Table makes sense, given that they are both what I’d consider R&B and soul albums. Elephant is a bit of a curveball, but I’d judge them both to have elements of blues. Saturn, I hadn’t heard of before I built the Album Discoverer, and upon listening, it’s a solid R&B album. I’m not sure how the Album Discoverer ranks Yankee Hotel Foxtrot as similar, or Transangelic Exodus. On first listen, any similarities weren’t clear to me, and this gave me a few ideas for how to improve the Album Discoverer, which I’ll discuss later in the post.
I also tried Once In A Lifetime by Talking Heads, to see what kind of recommendations I’d get in return. I wasn’t sure how it would handle it, given that Once In A Lifetime is a four disc box set.
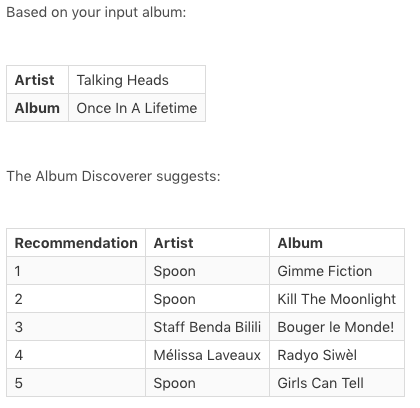
There are three Spoon albums listed here, which shares a few indie rock elements with Once in A Lifetime. I’m excited about the other two. I’d never listened to Mélissa Laveaux, but Radyo Siwèl is an album about the American occupation of Haiti, and the tracks are influenced by Haitian folk songs. Bouger Le Monde! by Staff Benda Bilili has tracks heavily influenced by Congolese dance music. If I had to guess, the recommender is picking up on Once in A Lifetime’s incorporation of polyrhythms, and using that to recommend these two albums.
Introducing the Album Discoverer Flask App
I put everything all together in a Flask App that takes a user input to provide recommendations. To try it out yourself, click here. The app currently has functionality for getting recommendations, as well as viewing the top 100 albums from Metacritic for inspiration.
To see how it works, you can check out the github repo for additional code and documentation. This was my first Flask app, and I cannot understate how useful it was to pickle objects from my analysis to use in the app.

Areas for Improvement
Not all recommendations from a recommendation system are useful. I don’t watch all of the shows Netflix recommends, and the Album Discoverer will certainly recommend albums that don’t seem relevant to the input album. Using the principal components analysis reduces interpretability on why certain albums were found to be similar, so in a future version, I’d like to use all thirteen features, which would give the user more insight on why certain albums were recommended.
There is also bias in the recommendations, because certain artists and genres are better represented in Metacritic’s rankings. The Album Discoverer is not great for soundtracks, which can feature a variety of different songs, and I can’t comment on how well it does for classical music (though it seems to do a good job at recommending other instrumental albums). I can address this by adding to the list of recommendations, to include more than just the top 1000 albums. This would hopefully increase the album variety, though not much can be helped if certain types of albums just aren’t appearing in Metacritic’s rankings.
Additionally, because Metacritic was launched in 2001, as far as I can tell, it doesn’t include any albums released prior to 2001, unless they have since been re-released. Subsequently, any album released prior to 2001 isn’t going to be recommended by the Album Discoverer, unless I add other sources to my album list.
There’s more work to improve the Album Discoverer, but it’s not a bad start for a project completed in a few weeks.
Try it, and let me know what you think, using one of the links in the sidebar! I’d love to hear whether you discovered a new favorite artist or album, got a particularly hilarious recommendation, or have some insight on some of the recommendations I mentioned in this post. Happy listening!
